2025-10-01
·Exoplanet Detection using Hybrid Ensemble ML Architecture and NASA Open Source Datasets
·ML & Astronomy
·4 min read
1. Introduction
This project presents an ensemble model developed for exoplanet detection. This methodology draws upon previous work done by Saha, R (2021), and Luz, T. S. F et al. (2024).
2. Machine Learning Workflow
The process follows the standard machine learning workflow.
2.1 Data Retrieval
Data is retrieved programmatically via the Table Access Protocol (TAP) service. The available tables can be found at:
https://exoplanetarchive.ipac.caltech.edu/docs/TAP/usingTAP.html
Astronomical Data Query Language (ADQL) is used to query records from the following tables:
- TOI (TESS Objects of Interest)
- KOI (Kepler Objects of Interest)
- K2Pandoc (K2 Planet Candidates)
The query structure follows this format:
query = "SELECT * FROM <table>"and with further encoding, the code below returns the data of interest in CSV format.
encoded_query = urllib.parse.quote(query)
# TAP URL
tap_url = f"https://exoplanetarchive.ipac.caltech.edu/TAP/sync?query={encoded_query}&format=csv"2.2 Data Preprocessing
In the data preprocessing phase, the data are explored to understand their key features. Looking at each dataset it is possible to plot the Transit Duration vs Transit Depth.
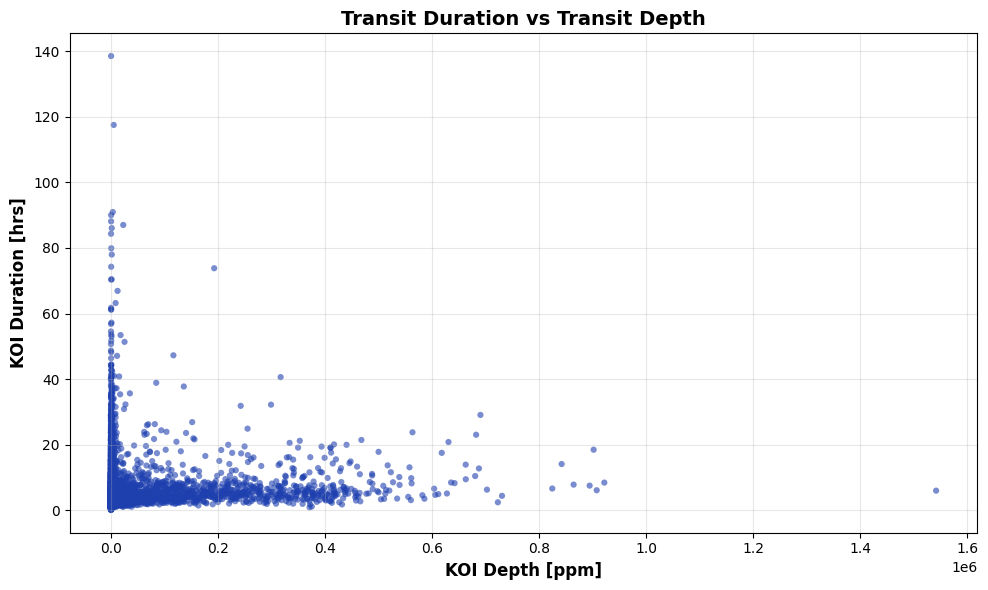
Fig. 1: Transit Duration vs Transit Depth for Kepler dataset.
Similarly for K2,
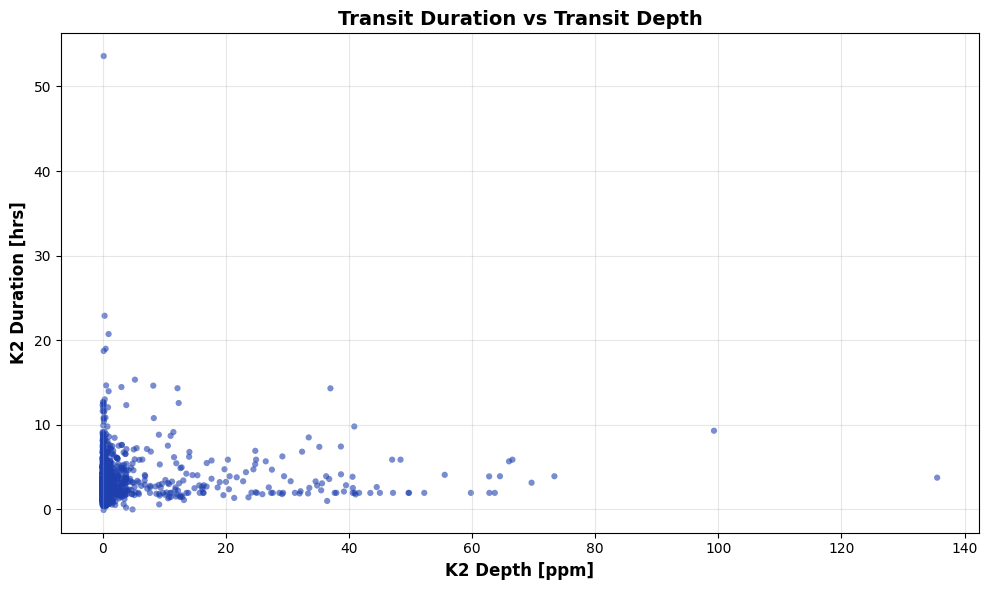
Fig. 2: Transit Duration vs Transit Depth for K2 dataset.
Finally for TESS,
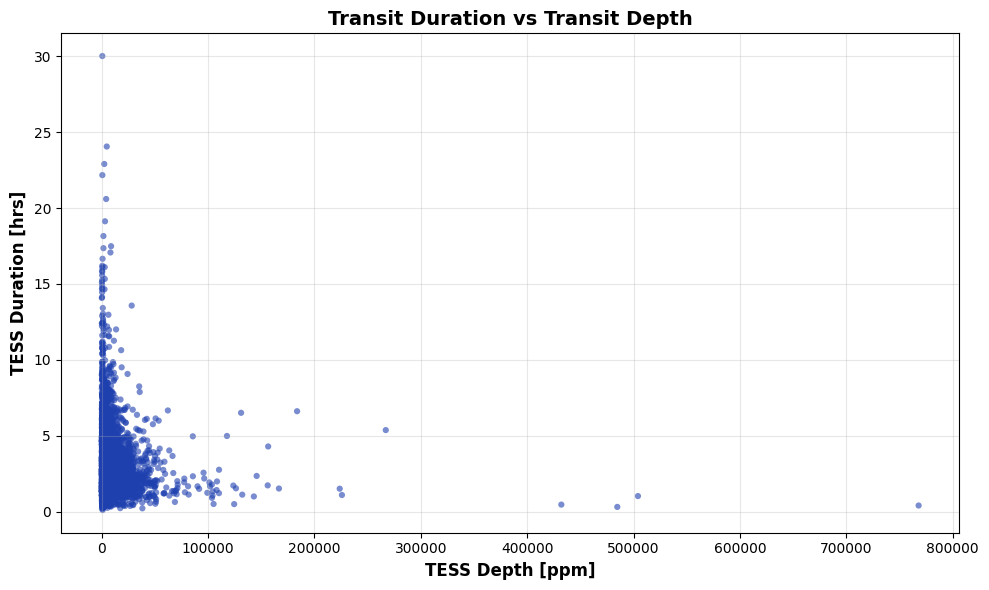
Fig. 3: Transit Duration vs Transit Depth for TESS dataset.
After removing all classes aside from CONFIRMED CANDIDATES we are left with:
KOI Disposition
Upon removing FALSE POSITIVES: 4725 rows
Remaining classes: koi_disposition
CONFIRMED 2746
CANDIDATE 1979
Name: count, dtype: int64K2 Disposition
Class distribution
Upon removing FALSE POSITIVES: 3689 rows
Remaining classes: disposition
CONFIRMED 2315
CANDIDATE 1374
Name: count, dtype: int64TESS Disposition
Upon removing FALSE POSITIVES: 5946 rows
Remaining classes: tfopwg_disp
PC 4679 # planetary candidates (CANDIDATES)
CP 684 # confirmed planets (CONFIRMED)
KP 583 # known planets (CONFIRMED)
Name: count, dtype: int64The candidates are mapped to 0 and confirmed planets are mapped to 1.
In the next step, null values are inspected. Columns with > 50% values missing are identified and dropped.
2.2.1 Feature Engineering & Selection
In the feature engineering phase, the datasets are processed to decrease dimensionality. The first step involves applying Pearson correlation. Subsequently, the dataset disposition is used as a target variable to identify the top 20-30 features.
2.2.2 Apply Scikit-learn Iterative Imputer
Despite the dimensionality being reduced, there are still null entries in the dataset. Dropping additional columns containing null values can cause loss of information, affecting the accuracy of the model. To address this problem, scikit-learn IterativeImputer is applied.
The iterative imputer computes p(x|y) where x represents the feature with missing values and y represents the features containing values.
2.3 Model Training
For model training, the dataset is split into training and testing datasets with an 80:20 ratio. Subsequently, StandardScaler is applied to the split data to prevent data leakage from the test dataset into the model.
A VotingClassifier is defined using an ensemble of five models.
ensemble_20 = VotingClassifier([
('rf', RandomForestClassifier(n_estimators=100, random_state=42)),
('xgb', XGBClassifier(random_state=42)),
('svm', SVC(probability=True, random_state=42)),
('lr', LogisticRegression(random_state=42, max_iter=2000)),
('deep_nn', MLPClassifier(hidden_layer_sizes=(200, 100, 50, 25, 10), max_iter=500, random_state=42))
], voting='soft')2.4 Results
The Hybrid ML Ensemble Architecture provides improved performance for the 30 top features compared to the top-20 features model for Kepler and K2 datasets. This binary classification approach yields the following accuracy results:
| Dataset | Features | Accuracy |
|---|---|---|
| Kepler | 30 | 88.4% |
| Kepler | 20 | 87.2% |
| K2 | 30 | 99.3% |
| K2 | 20 | 99.2% |
| TESS | 20 | 86.1% |
| TESS | 30 | 85.8% |
3. Notebooks
View Kepler Notebook
View K2 Notebook
View TESS Notebook
4. References
Saha, R 2021. Comparing Classification Models on Kepler Data. arXiv preprint arXiv:2101.01904 [astro-ph.EP], viewed 5/10/2025, https://arxiv.org/abs/2101.01904.
Luz, T. S. F., Braga, R. A. S., & Ribeiro, E. R. (2024). Assessment of Ensemble-Based Machine Learning Algorithms for Exoplanet Identification. Electronics, 13(19), 3950. https://doi.org/10.3390/electronics13193950
Topics
- Exoplanet Detection
- Photometric Data Analysis
- NASA Space Mission Data
- Astronomical Data Analysis
- Time Series Analysis
- Transit Detection
Tech Stack
- Python
- Scikit-learn
- TensorFlow/PyTorch
- Pandas
- NumPy
- Matplotlib/Plotly
- Astronomical Data Query Language (ADQL)